1. Use LoRA model from artificialguybr. 2. Use customized model Anything.
Method
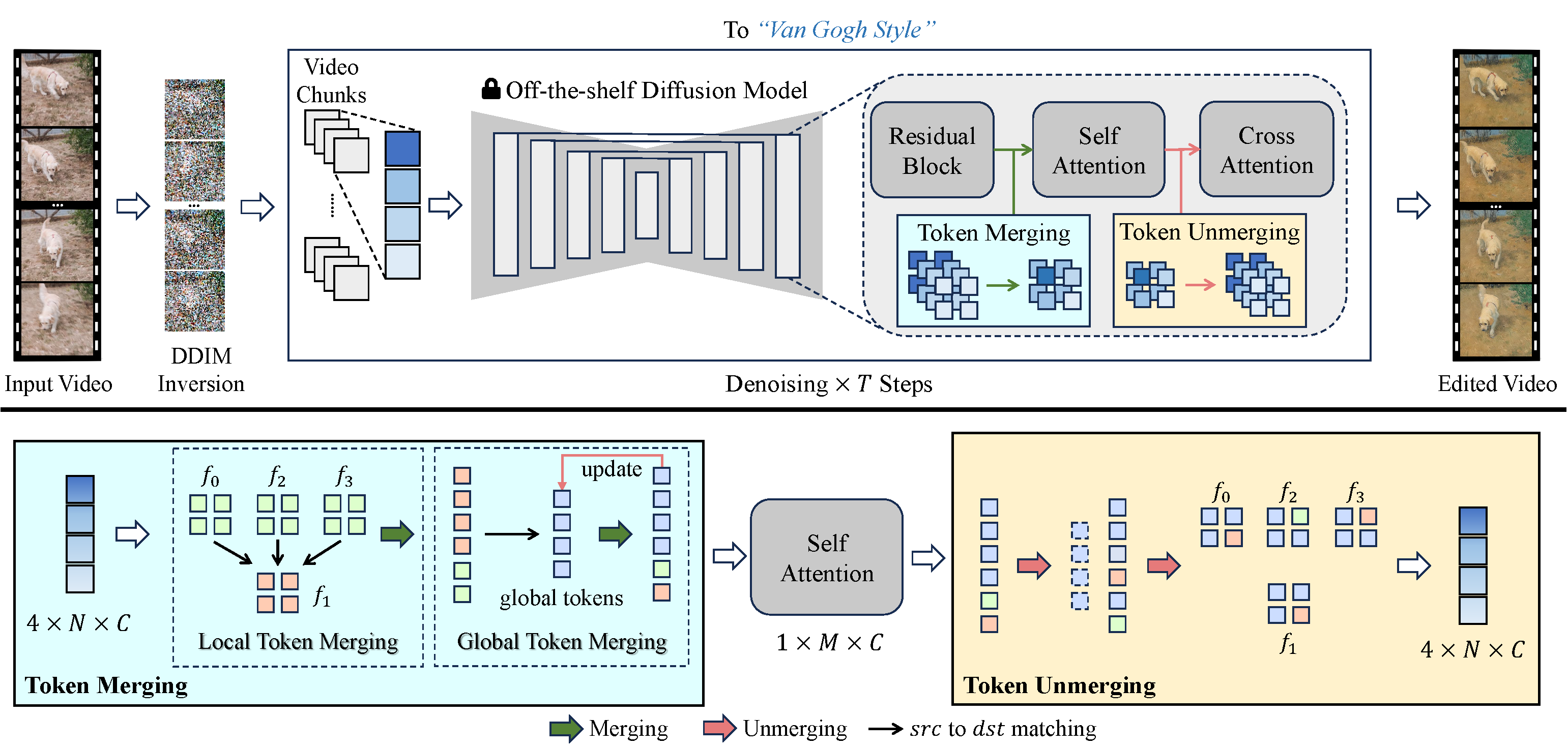
Given an input source video and a text prompt, our proposed VidToMe generates an edited video according to the prompt using a pretrained text-to-image diffusion model. The critical idea is to merge similar tokens across multiple frames in self-attention modules to achieve temporal consistency in generated videos.
Top: VidToMe pipeline. Starting from DDIM inverted noise latent, we denoise the video frames with the diffusion model combined with an existing controlling method. The video token merging is applied before self-attention blocks.
Bottom: Video Token Merging. Given the self-attention input tokens, we first merge tokens in the video chunk (Local Token Merging). Then, a global token set is combined to enable inter-chunk token sharing (Global Token Merging). After joint self-attention on the merged token set, the output tokens are restored to their original size by reversing the merging process.
VidToMe Editing Results
Left: Input Video; Right: Edit Video.
To "Van Gogh Style"
To "Rainbow-colored Origami
Flamingo"
To "Oil Painting Style"
To "GPU in a Computer"
To "Comic Book, Black and White
Pencil Sketch"
To "White Ancient Greek
Sculpture"
To "Pop Art Style"
To "Volcano, Spewing Lava"
Efficiency
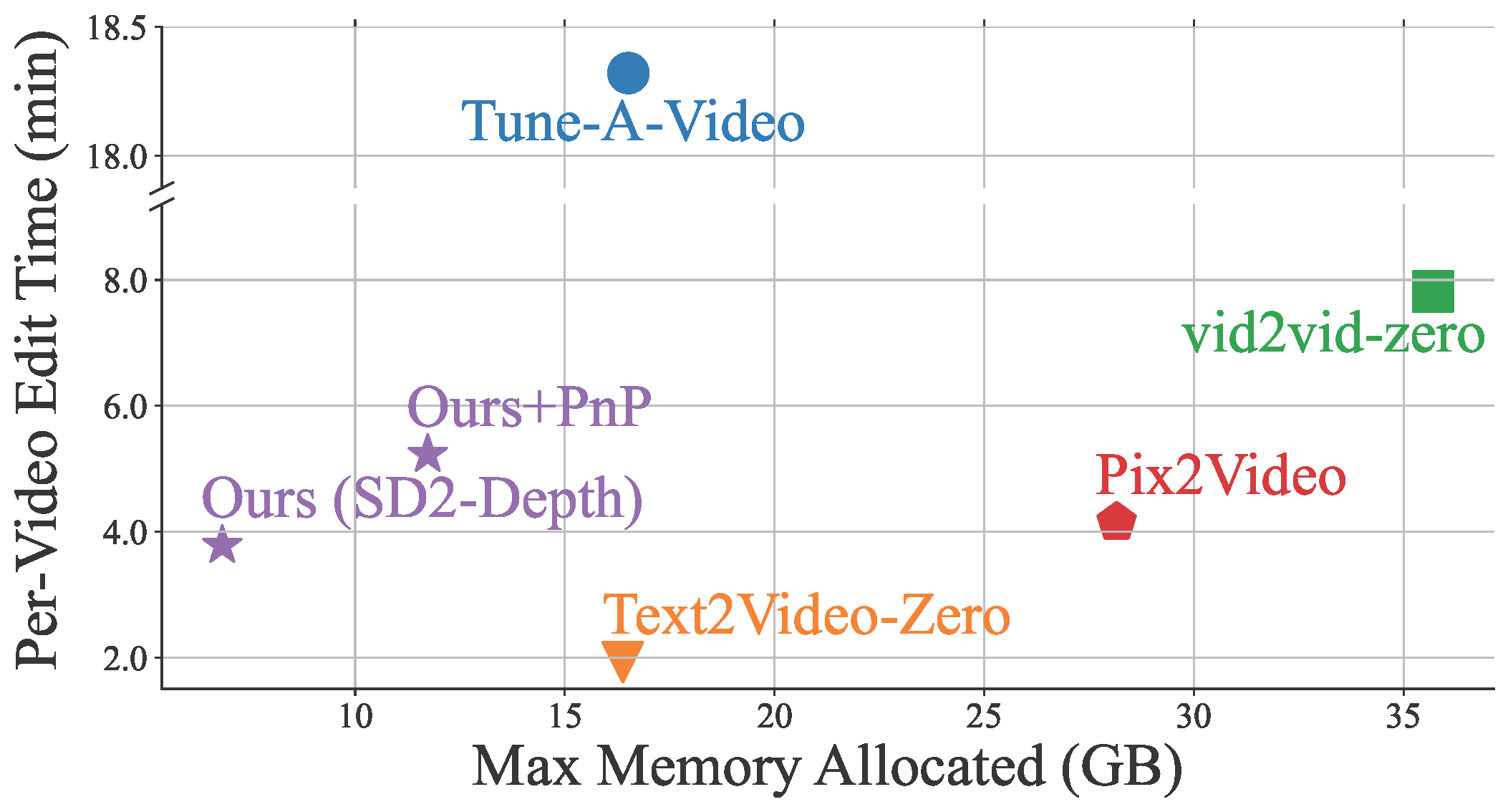
Merging multi-frame tokens reduces the temporal redundancy in video frames, improving memory and computational efficiency. Therefore, compared with baseline methods, VidToMe consumes less memory while generating videos quickly.
Using Customized Models
Video Presentation
BibTeX
@article{li2023vidtome,
title={VidToMe: Video Token Merging for Zero-Shot Video Editing},
author={Li, Xirui and Ma, Chao and Yang, Xiaokang and Yang, Ming-Hsuan},
booktitle={arXiv preprint arxiv:2312.10656},
year={2023}
}[1] Narek Tumanyan, Michal Geyer, et al. “Plug-and-play diffusion features for text-driven image-to-image translation”. In CVPR. 2023. [2] Robin Rombach, Andreas Blattmann, et al. “High-resolution image synthesis with latent diffusion models”. In CVPR. 2022. [3] Levon Khachatryan, Andranik Movsisyan, et al. “Text2video-zero: Text-to-image diffusion models are zero-shot video generators”. arXiv preprint arXiv:2303.13439. 2023. [4] Jay Zhangjie Wu, Yixiao Ge, et al. “Tune-a-video: One-shot tuning of image diffusion models for text-to-video generation”. In ICCV, 2023. [5] Wen Wang, kangyang Xie, et al. “Zero-shot video editing using off-the-shelf image diffusion models”. arXiv preprint arXiv:2303.17599. 2023. [6] Duygu Ceylan, Chun-Hao P Huang, and Niloy J Mitra. “Pix2video: Video editing using image diffusion”. In ICCV. 2023. [7] Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. “Adding conditional control to text-to-image diffusion models”. In ICCV. 2023. [8] Edward J. Hu and Yelong Shen, et al. “LoRA: Low-Rank Adaptation of Large Language Models”. In ICLR. 2021.